Contents
Overview
The original dataset consists of 122 songs MedleyDB 2.0 adds 74 new multitracks to the dataset - totaling to 196 multitracks. 108 of the original multitracks include melody annotations.The remaining 14 songs do not have a discernible melody and thus were not appropriate for melody extraction. We include these 14 songs in the dataset because of their use for other applications including instrument ID, source separation and automatic mixing.
Each song in MedleyDB is available under a Creative Commons Attribution - NonCommercial - ShareAlike license, which allows the release of the audio and annotations for noncommercial purposes.
The songs in MedleyDB were obtained from the following sources:
The majority of these songs were recorded in professional studios and mixed by experienced engineers.
Each song in MedleyDB is available under a Creative Commons Attribution - NonCommercial - ShareAlike license, which allows the release of the audio and annotations for noncommercial purposes.
The songs in MedleyDB were obtained from the following sources:
- Independent Artists (30 songs)
- NYU's Dolan Recording Studio (32 songs)
- Weathervane Music (25 songs)
- Music Delta (35 songs)
The majority of these songs were recorded in professional studios and mixed by experienced engineers.
|
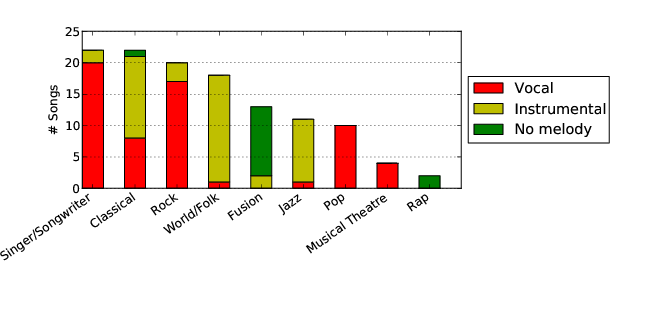
MedleyDB contains songs of a variety of musical genres, and has a roughly even split between vocal and instrumental songs. The genres are based on nine generic genre labels. Note that some genres such as Singer/Songwriter, Rock and Pop are strongly dominated by vocal songs, while others such as Jazz and World/Folk are mostly instrumental. Also note that the Rap and most of the Fusion songs do not have melody annotations.
|
|
|
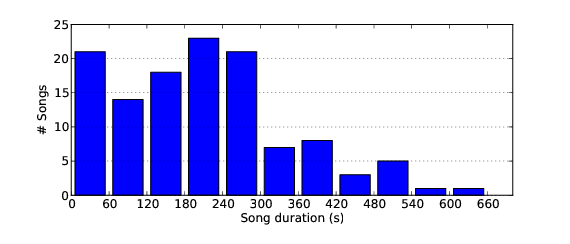
A total of 105 out of the 122 songs in the dataset are full length songs, and the majority of these are between 3 and 5 minutes long. Most recordings that are under 1 minute long are excerpts and were obtained by Music Delta. These excerpts typically contain a single (complete) verse or chorus, but do not have the musical structure of a full length song.
|
|
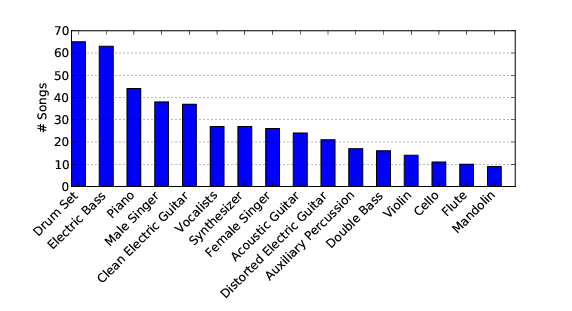
This plot shows the most represented instruments in the dataset. Unsurprisingly, drums, bass, piano, vocals and guitars dominate the distribution. This plot was generated using the instrument labels assigned to the stems of each song.
MedleyDB contains a number of tracks with non-western instruments including the tabla, oud, dizi, and erhu. |
|
For the sections below, it may be helpful to download the MedleyDB sample from the Downloads page, which has the same structure as the full dataset.
The dataset itself has two top level folders called "Audio" and "Annotations". Audio contains folders for each song, and Annotations contains folders for each type of annotation. The audio content includes a mix of the song, the song's "stems" (processed individual instrument tracks), and "raw" audio (unprocessed recordings).
The contents a each song in MedleyDB are located in "Audio" in a folder called "ArtistName_TrackName". This folder contains the following:
The yaml file contains the song's metadata, the "_MIX.wav" file is the track's mix, the "_RAW" folder contains the raw audio, and the "_STEMS" folder contains the stems.
The dataset itself has two top level folders called "Audio" and "Annotations". Audio contains folders for each song, and Annotations contains folders for each type of annotation. The audio content includes a mix of the song, the song's "stems" (processed individual instrument tracks), and "raw" audio (unprocessed recordings).
The contents a each song in MedleyDB are located in "Audio" in a folder called "ArtistName_TrackName". This folder contains the following:
- ArtistName_TrackName_METADATA.yaml
- ArtistName_TrackName_MIX.wav
- ArtistName_TrackName_RAW/
- ArtistName_TrackName_STEMS/
The yaml file contains the song's metadata, the "_MIX.wav" file is the track's mix, the "_RAW" folder contains the raw audio, and the "_STEMS" folder contains the stems.
Audio
Three types of audio content are given for each song: a mix, stems, and raw audio. All types of audio files are .wav files with a sample rate of 44.1 kHz and a bit depth of 16. The mix and stems are stereo and the raw audio files are mono.
|
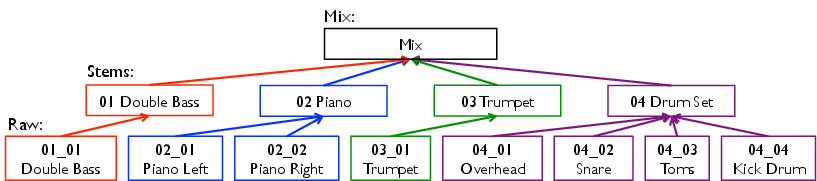
From a hierarchical viewpoint, a mix is comprised of a set of stems, and each stem is comprised of a set of raw audio files. A stem may be created from one or multiple raw audio files.
A stereo stem created from a single raw audio file incorporates any panning information. |
|
The mix is labeled in the form "ArtistName_TrackName_MIX.wav". These mixes may or may not be mastered. Unfortunately we do not have labels for which mixes are mastered and which are not.
Stems are labeled in the form "ArtistName_TrackName_STEM_<stem index>.wav", where the stem indices 1 through n are assigned (in no particular order) to the n stems. Raw audio files are labeled in the form "Artist_Name_TrackName_RAW_<stem index>_<raw index>.wav", where <stem index> is the index of the corresponding stem and the raw indices 1 through m are assigned to the m raw files corresponding to that particular stem. All metadata relating to the audio files is contained in the metadata file.
Raw audio is "raw" in the sense that no effects are applied to the recording (with the exception of time shifts to preserve alignment with the stems). Note that we do not consider timing adjustments to be "effects", and that the raw audio is edited in time to match the timing of the final stem (i.e. there are no events present in the raw audio that are not present in the corresponding stem). Stems contain any effects applied to the collection of raw audio files, including panning, reverb, equalization, or compression.
Some songs in the dataset were recorded in a "live" group setting, and some were recorded with isolation booths. Those recorded in a group setting have bleed from other instruments in some or all of the stems and raw audio files. The presence or absence of bleed is indicated in the metadata for each song.
Stems are labeled in the form "ArtistName_TrackName_STEM_<stem index>.wav", where the stem indices 1 through n are assigned (in no particular order) to the n stems. Raw audio files are labeled in the form "Artist_Name_TrackName_RAW_<stem index>_<raw index>.wav", where <stem index> is the index of the corresponding stem and the raw indices 1 through m are assigned to the m raw files corresponding to that particular stem. All metadata relating to the audio files is contained in the metadata file.
Raw audio is "raw" in the sense that no effects are applied to the recording (with the exception of time shifts to preserve alignment with the stems). Note that we do not consider timing adjustments to be "effects", and that the raw audio is edited in time to match the timing of the final stem (i.e. there are no events present in the raw audio that are not present in the corresponding stem). Stems contain any effects applied to the collection of raw audio files, including panning, reverb, equalization, or compression.
Some songs in the dataset were recorded in a "live" group setting, and some were recorded with isolation booths. Those recorded in a group setting have bleed from other instruments in some or all of the stems and raw audio files. The presence or absence of bleed is indicated in the metadata for each song.
Metadata
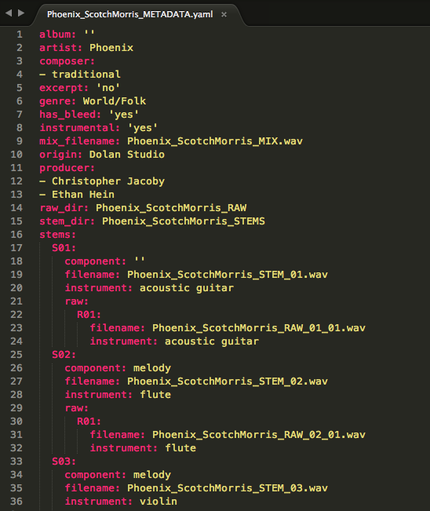
Overview
The metadata is provided in a YAML file, which is both dictionary-like and is (actually) human readable. The metadata contains the following fields:
Each stem, for example "S01" has the following fields:
Once again, each raw file, for example "R01" has the following fields:
We go into additional detail about some of these fields below.
Excerpt
Possible values:
Genre
Possible values:
Because the notion of genre is quite subjective, we use somewhat general genre labels. These labels should not be considered to be "precise" genre labels. There are many instances where a song could have fallen in multiple genres, and the choices were made so that each genre would be as acoustically homogenous as possible. That being said, our "pop" label (for example) may be quite different than the pop label in another dataset.
Has Bleed
Possible values:
Instrumental
Possible values:
Origin
Possible values:
Component
Possible values:
Instrument
The possible values for this label are based on this taxonomy, with the addition of the label "Main System". The label "Main System" indicates a stem representing a recording of an entire ensemble. For example, when recording classical music live, it is common to use a "main" microphone system to record the ensemble sound and also mic the instruments individually. The main system is often a primary contributor to the mix, and the individual instrument microphones are used for balance.
Some taxonomy labels of note:
The taxonomy is by no means exhaustive, and will be appended as needed for future versions.
The metadata is provided in a YAML file, which is both dictionary-like and is (actually) human readable. The metadata contains the following fields:
- album: the album the song was released on (optional)
- artist: the artist's full name
- composer: the composer of the song (optional)
- excerpt: indicates if the song is an excerpt
- genre: the genre of the song
- has_bleed: indicates if the stems in the song have bleed
- instrumental: indicates if the song is instrumental
- mix_filename: the name of the song's mix file
- origin: the source from which the song was obtained
- producer: the song's producer (optional)
- raw_dir: the name of the folder containing the raw audio
- stem_dir: the name of the folder containing the stems
- title: the full title of the song
- website: the artist's website (optional)
- stems: stem metadata (a list of dictionaries keyed by stem index)
Each stem, for example "S01" has the following fields:
- component: indicates if the stem contains melody or bass
- filename: the name of the stem's audio file
- instrument: the stem's instrument label
- raw: raw audio metadata (a list of dictionaries keyed by raw index)
Once again, each raw file, for example "R01" has the following fields:
- filename: the name of the raw audio file
- instrument: the raw audio file's instrument label
We go into additional detail about some of these fields below.
Excerpt
Possible values:
- yes
- no
Genre
Possible values:
- Singer/Songwriter
- Classical
- Rock
- World/Folk
- Fusion
- Jazz
- Pop
- Musical Theatre
- Rap
Because the notion of genre is quite subjective, we use somewhat general genre labels. These labels should not be considered to be "precise" genre labels. There are many instances where a song could have fallen in multiple genres, and the choices were made so that each genre would be as acoustically homogenous as possible. That being said, our "pop" label (for example) may be quite different than the pop label in another dataset.
Has Bleed
Possible values:
- yes
- no
Instrumental
Possible values:
- yes
- no
Origin
Possible values:
- Dolan Studio
- Weathervane Music
- Music Delta
- Independent Artist
Component
Possible values:
- melody
- bass
- [none]
Instrument
The possible values for this label are based on this taxonomy, with the addition of the label "Main System". The label "Main System" indicates a stem representing a recording of an entire ensemble. For example, when recording classical music live, it is common to use a "main" microphone system to record the ensemble sound and also mic the instruments individually. The main system is often a primary contributor to the mix, and the individual instrument microphones are used for balance.
Some taxonomy labels of note:
- violin section: more than one violin
- viola section: more than one viola
- cello section: more than one cello
- string section: more than one string instrument (e.g. 2 violins and 1 viola)
- tack piano: an intentionally out of tune or acoustically altered piano
- flute section: more than one flute
- clarinet section: more than one clarinet
- trumpet section: more than one trumpet
- french horn section: more than one french horn
- trombone section: more than one trombone or bass trombone
- brass section: more than one brass instrument (not including saxophones or other woodwinds)
- horn section: more than one brass or woodwind instrument (must be a mixture of brass & woodwinds)
- vocalists: more than one singer (may be a mixture of male and female)
- auxiliary percussion: more than one percussion instrument (beyond drum set components)
- drum machine: a computer generated drum track from drum set samples, time aligned to a grid
- clean electric guitar: a non-distorted electric guitar
- distorted electric guitar: an electric guitar with noticeable effects processing
- electronic piano: a keyboard using a sound setting that is piano-like
- synthesizer: a keyboard using a (melodic) sound setting that is not piano-like.
- fx/processed sound: sound effects or ambient noise
- scratches: record scratches
- sampler: similar to drum machine but with samples that are not drum set samples (eg. vocal snippets)
The taxonomy is by no means exhaustive, and will be appended as needed for future versions.
Annotations
Instrument Activations
The instrument activations indicate for each stem at which time frames the instrument/voice in the stem is active. For each track the instrument activations are provided in two forms in the directory “Annotations/Instrument_Activations”.
These annotations were generated using a standard envelope following technique on each stem, consisting of half-wave rectification, compression, smoothing, and down-sampling. The resulting envelopes were normalized to account for overall signal energy and total number of sources, resulting in the t by m matrix H, where t is the number of analysis frames, and m is the number of instruments in the mix. For the ith instrument, the confidence of its activations as a function of time can be approximated via a logistic function:
These annotations were generated using a standard envelope following technique on each stem, consisting of half-wave rectification, compression, smoothing, and down-sampling. The resulting envelopes were normalized to account for overall signal energy and total number of sources, resulting in the t by m matrix H, where t is the number of analysis frames, and m is the number of instruments in the mix. For the ith instrument, the confidence of its activations as a function of time can be approximated via a logistic function:
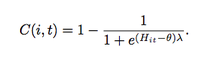
Where lambda controls the slope of the function, and theta controls the threshold of activation. Frames where instrument i is considered active are those for which C(i,t) is greater than or equal to 0.5. No manual corrections were performed on these annotations.
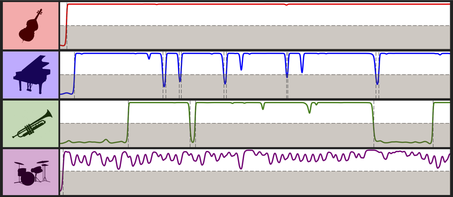
Activation Confidence Annotations
The activation confidence annotations are given as a .lab file, and indicate the confidence values C(i,t) as described above for each stem. The rows of the lab files are in the form [time (sec), stem1_confidence, stem2_confidence, ..., stemN_confidence]. The sources are indicated in the header by their source id (e.g. S02) and corresponds with the ID's in the metadata file.
Source ID Annotations
The source ID annotations indicate time intervals where a particular instrument label is active. They are given as lab files where the rows are in the form [start_time (sec), end_time (sec), instrument label]. They are listed first by instrument label, and then by start time.
These annotations were generated by binarizing the confidence annotations (active: confidence >= 0.5, not active: confidence < 0.5), and grouping continuous sequences of 1's into a single time range indicated by start and end time.
The activation confidence annotations are given as a .lab file, and indicate the confidence values C(i,t) as described above for each stem. The rows of the lab files are in the form [time (sec), stem1_confidence, stem2_confidence, ..., stemN_confidence]. The sources are indicated in the header by their source id (e.g. S02) and corresponds with the ID's in the metadata file.
Source ID Annotations
The source ID annotations indicate time intervals where a particular instrument label is active. They are given as lab files where the rows are in the form [start_time (sec), end_time (sec), instrument label]. They are listed first by instrument label, and then by start time.
These annotations were generated by binarizing the confidence annotations (active: confidence >= 0.5, not active: confidence < 0.5), and grouping continuous sequences of 1's into a single time range indicated by start and end time.
Melody Annotations
The melody annotations provided in MedleyDB are "continuous f0" annotations. Each time frame is given a frequency value in Hz, creating pitch contours. These annotations can be found in the directory “Annotations/Melody_Annotations/”, in the folders "MELODY1", "MELODY2", and "MELODY3".
Three different types of melody annotations are given based upon the definitions of melody described below.
General
All melody annotations were generated using pitch annotations of individual stems. The pitch annotations can be found in the directory “Annotations/Pitch_Annotations”. For more information on the pitch annotations, refer to the section below titled “Pitch Annotations”.
Format
The annotations are given as comma separated files. For all 3 types of melody, the first column is the time stamp. For Melody 1 and Melody 2, the second column is the pitch value of the melody. For Melody 3, columns 2 through n are pitch annotations of each of the melodic voices, ranked by prominence.
Melody 1
Melody Definition: “The f0 curve of the predominant melodic line drawn from a single source”
This definition of melody is the same as the definition used in MIREX, and is well suited for tracks where there is a single predominant melodic source, such as in the excerpt below. This definition ignores cases where for example, a flute and clarinet play the melody at different points in a piece. In this case, only the pitch of one of the two instruments would appear in the melody.
Three different types of melody annotations are given based upon the definitions of melody described below.
General
- first time stamp: 0 seconds
- time stamp step size: ~5.8 milliseconds (256 samples at a sample rate of 44100)
- time stamps are in units of seconds
- pitch values are in Hz
- a pitch of 0.0 indicates no pitch
All melody annotations were generated using pitch annotations of individual stems. The pitch annotations can be found in the directory “Annotations/Pitch_Annotations”. For more information on the pitch annotations, refer to the section below titled “Pitch Annotations”.
Format
The annotations are given as comma separated files. For all 3 types of melody, the first column is the time stamp. For Melody 1 and Melody 2, the second column is the pitch value of the melody. For Melody 3, columns 2 through n are pitch annotations of each of the melodic voices, ranked by prominence.
Melody 1
Melody Definition: “The f0 curve of the predominant melodic line drawn from a single source”
This definition of melody is the same as the definition used in MIREX, and is well suited for tracks where there is a single predominant melodic source, such as in the excerpt below. This definition ignores cases where for example, a flute and clarinet play the melody at different points in a piece. In this case, only the pitch of one of the two instruments would appear in the melody.
This type of melody annotation is the pitch of the stem with the most predominant melodic source. The choice of most predominant melodic stem was made by the same annotator across the dataset. The ranking of stems by melodic prominence for each track is given in the directory “Annotations/Stem_Rankings”, with the most predominant stem labeled with rank “1”.
This definition of melody works when there is one clear predominant melodic source, such as in a pop song with a clear vocal melody. However, this definition is lacking for more complex music, where multiple voices/instruments may play the melody during the course of the song.
Melody 2
Melody Definition: “The f0 curve of the predominant melodic line drawn from multiple sources”
This definition applies to a wider range of music than melody 1, including cases where there are multiple equally predominant melodic sources such as in the example below where the male and female vocalists share the melody. Note that this definition still forces only one source to be "the" melody at each point in time; at the end of this excerpt where the two vocalists are in harmony, it must be decided which one is more melodic at that point.
This definition of melody works when there is one clear predominant melodic source, such as in a pop song with a clear vocal melody. However, this definition is lacking for more complex music, where multiple voices/instruments may play the melody during the course of the song.
Melody 2
Melody Definition: “The f0 curve of the predominant melodic line drawn from multiple sources”
This definition applies to a wider range of music than melody 1, including cases where there are multiple equally predominant melodic sources such as in the example below where the male and female vocalists share the melody. Note that this definition still forces only one source to be "the" melody at each point in time; at the end of this excerpt where the two vocalists are in harmony, it must be decided which one is more melodic at that point.
This type of melody annotation was generated by first annotating the predominant melodic stem over time. For example:
start_time, end_time, stem_index
0.0, 23.4, 4
23.4, 103.9, 9
103.9, 108.0, 4
etc.
These melody intervals by stem are given in the directory “Annotations/Stem_Intervals”.
For each time interval, the pitch annotation of the indicated stem is assigned to the melody. Thus, at each point in time, this type of melody annotation gives the pitch of the current most predominant melodic source.
This melody annotation is the best balance between completeness of melody and simplicity (only one melodic source may be present at a time). Even so, this definition cannot capture more complicated music, where multiple sources may be playing melodic content at once. For example, contrapuntal music seldom has a single clear melody, and more commonly pop music often has two vocalists singing the melody in octaves.
Melody 3
Melody Definition: “The f0 curves of all melodic lines drawn from multiple sources”
This definition can be applied to virtually all melodic music, and considers cases where multiple sources may be playing melodic content simultaneously. For example in the excerpt below, there are phrases where the piccolo and violins play the melody in different octaves. This definition also works for more complex interwoven melodies, such as in Bach Fugues.
start_time, end_time, stem_index
0.0, 23.4, 4
23.4, 103.9, 9
103.9, 108.0, 4
etc.
These melody intervals by stem are given in the directory “Annotations/Stem_Intervals”.
For each time interval, the pitch annotation of the indicated stem is assigned to the melody. Thus, at each point in time, this type of melody annotation gives the pitch of the current most predominant melodic source.
This melody annotation is the best balance between completeness of melody and simplicity (only one melodic source may be present at a time). Even so, this definition cannot capture more complicated music, where multiple sources may be playing melodic content at once. For example, contrapuntal music seldom has a single clear melody, and more commonly pop music often has two vocalists singing the melody in octaves.
Melody 3
Melody Definition: “The f0 curves of all melodic lines drawn from multiple sources”
This definition can be applied to virtually all melodic music, and considers cases where multiple sources may be playing melodic content simultaneously. For example in the excerpt below, there are phrases where the piccolo and violins play the melody in different octaves. This definition also works for more complex interwoven melodies, such as in Bach Fugues.
This definition is the most general, giving all possible melodies at a time. While comprehensive, this definition also adds considerable complexity to the problem of melody extraction, including regarding any type of training or evaluation based on this definition. This annotation is simply an ordered concatenation of the pitch annotations of the stems containing melody. The ordering of predominance is given in the directory “Annotations/Stem_Rankings”.
Visualizing the Annotations
These annotations can be plotted and sonified within Tony by loading in the corresponding mix, selecting File > Import Pitch Track…, and selecting the .csv melody annotation file.
Visualizing the Annotations
These annotations can be plotted and sonified within Tony by loading in the corresponding mix, selecting File > Import Pitch Track…, and selecting the .csv melody annotation file.
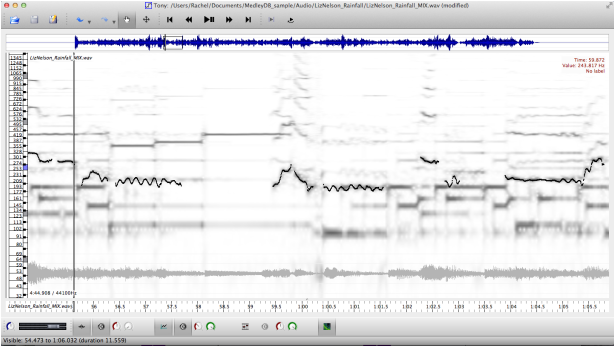
Pitch Annotations
These annotations were not created as "stand-alone" annotations, but rather as a necessary first step for generating melody annotations. They are provided as part of the dataset for completeness.
The pitch annotations provided are “continuous” f0 annotations. Each small time frame is given a frequency value in Hz, creating pitch contours. Note that the monophonic pitch annotations given here may not correspond to a monophonic audio source. For example, a piano which plays melodic content in addition to accompaniment will have a single pitch annotation consisting of the monophonic melodic line.
General
Format
The pitch annotations are given as comma separated files where column 1 is time in seconds and column 2 is pitch in Hz.
Annotation Protocols
The pitch was annotated only when melodic content was present. The choice of what content was “melodic” was determined by the annotators, with the rule of thumb that if they were in doubt to call it melodic. If the stem contained multiple pitches (for example a piano playing both melody and accompaniment, the predominant (monophonic) melodic line was annotated.
Pitch annotations were created using Tony versions 0.5 and 0.6. Reverb tail and consonant vocal sounds were considered un-pitched.
Each track was assigned to one of 5 annotators. The assigned annotator created pitch annotations for all melodic stems for the track. Once complete, these annotations were checked and possibly cleaned by a different annotator. The validated annotations are considered the final annotations.
Visualizing the Annotations
These annotations can be plotted and sonified within Tony by loading the corresponding stem, selecting File > Import Pitch Track…, and selecting the .csv pitch annotation file.
The pitch annotations provided are “continuous” f0 annotations. Each small time frame is given a frequency value in Hz, creating pitch contours. Note that the monophonic pitch annotations given here may not correspond to a monophonic audio source. For example, a piano which plays melodic content in addition to accompaniment will have a single pitch annotation consisting of the monophonic melodic line.
General
- only pitched time stamps are given
- first time stamp: at first timestamp with a nonzero pitch value
- time stamp step size: ~5.8 milliseconds (256 samples at a sample rate of 44100)
- time stamps are in units of seconds
- pitch values are in Hz
Format
The pitch annotations are given as comma separated files where column 1 is time in seconds and column 2 is pitch in Hz.
Annotation Protocols
The pitch was annotated only when melodic content was present. The choice of what content was “melodic” was determined by the annotators, with the rule of thumb that if they were in doubt to call it melodic. If the stem contained multiple pitches (for example a piano playing both melody and accompaniment, the predominant (monophonic) melodic line was annotated.
Pitch annotations were created using Tony versions 0.5 and 0.6. Reverb tail and consonant vocal sounds were considered un-pitched.
Each track was assigned to one of 5 annotators. The assigned annotator created pitch annotations for all melodic stems for the track. Once complete, these annotations were checked and possibly cleaned by a different annotator. The validated annotations are considered the final annotations.
Visualizing the Annotations
These annotations can be plotted and sonified within Tony by loading the corresponding stem, selecting File > Import Pitch Track…, and selecting the .csv pitch annotation file.
Stem Time Intervals
These annotations were not created as "stand-alone" annotations, but rather as a necessary first step for generating melody annotations. They are provided as part of the dataset for completeness.
These annotations indicate the predominant melodic stem for each time interval. The boundaries for each time interval occur when the primary melodic content changes voice.
The annotations were created in Audacity. For consistency, one annotator created these annotations for every track in the dataset.
Format
These annotations are given as tab separated files where column 1 is interval start time, column 2 is interval end time, and column 3 is the index of the stem with the primary melodic content during that time interval.
These annotations indicate the predominant melodic stem for each time interval. The boundaries for each time interval occur when the primary melodic content changes voice.
The annotations were created in Audacity. For consistency, one annotator created these annotations for every track in the dataset.
Format
These annotations are given as tab separated files where column 1 is interval start time, column 2 is interval end time, and column 3 is the index of the stem with the primary melodic content during that time interval.
Stem Rankings
These annotations were not created as "stand-alone" annotations, but rather as a necessary first step for generating melody annotations. They are provided as part of the dataset for completeness.
These annotations indicate the ranking of melodic predominance for each of the stems containing melody. For example, if there are n stems with melodic content, each of these stems are ranked from 1 to n from most to least predominant melody. A track with 2 melodic stems, say vocals and guitar where the vocals have the melody for all but a solo section where the guitar has a solo, vocals would be given rank 1 and guitar would be given rank 2.
For consistency, one annotator labeled the rankings for every track in the dataset.
Format
These annotations are give as comma separated files where column 1 is the pitch annotation file name and column 2 is the rank.
These annotations indicate the ranking of melodic predominance for each of the stems containing melody. For example, if there are n stems with melodic content, each of these stems are ranked from 1 to n from most to least predominant melody. A track with 2 melodic stems, say vocals and guitar where the vocals have the melody for all but a solo section where the guitar has a solo, vocals would be given rank 1 and guitar would be given rank 2.
For consistency, one annotator labeled the rankings for every track in the dataset.
Format
These annotations are give as comma separated files where column 1 is the pitch annotation file name and column 2 is the rank.
Medley DB 2.0
MedleyDB 2.0 introduces the following key features:
- 74 new multitrack recordings
- MedleyDB Manager: an online, collaborative ticketing system for managing the lifecycle of a multitrack
- MedleyDeBugger: a lightweight application to check multitracks for common errors prior to entering the dataset
- Annotations and metadata now available on Github
New Data
MedleyDB 2.0 brings 74 new multitrack recordings to the dataset. The new multitracks come from a variety of genres, with classical and jazz being the most dominant.
MedleyDB Manager
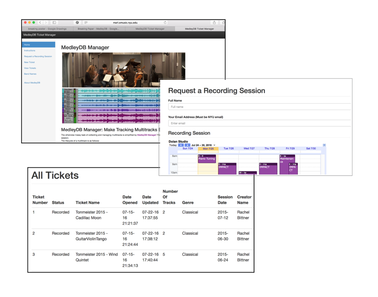
Prior to the release of MedleyDB Manager, multitrack recordings were often lost in long email chains and lack of follow through between artists, recording engineers, and dataset managers. As we began to develop MedleyDB manager, we identified the following seven stages in the life cycle of a multitrack:
- artist expresses interest in contributing to the database
- recording session is scheduled
- session is recorded
- engineer mixes session
- session exported to WAV files
- tracks are processed through multitrack applications
- track finally added to MedleyDB database
MedleyDeBugger
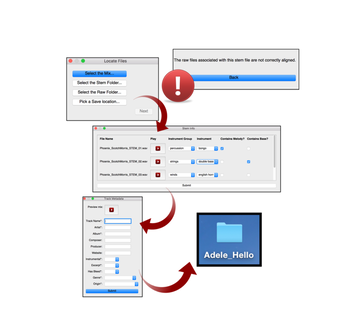
In the initial release of MedleyDB, we found that submitted multitracks often contained errors ranging from incorrect alignment of stem files to their associated mix (recall raw -> stem -> final mix structure), to silent files or data loss upon exporting multitracks from ProTools. Additionally the need to manually rename files and create a metadata file by hand presents a lot of room for user error. To address these potential errors and improve consistency and accuracy within the dataset, we created MedleyDeBugger, an application that automatically checks the submitted audio files for errors and establishes a standardized naming system.
Files processed by MedleyDeBugger are checked for the following common errors:
Upon completion of the error checking process, users are prompted to give information about the naming schema of their files. Finally, a folder containing the raw, stem and mix files is created. The application also reorganizes the files into a standardized structure and naming system while simultaneously creating a metadata file. We hope that the creation of MedleyDeBugger will increase consistency and accuracy of the multitracks in the dataset such that they are as clean and organized as possible for dataset users to utilize.
Files processed by MedleyDeBugger are checked for the following common errors:
- silent files (feature available to automatically remove any silent files)
- file format (number of channels, bit depth, sample rate)
- length consistency (i.e. does the length of each raw file = length of final mix)
- alignment (i.e. do the stem files line up with the final mix)
- inclusion (i.e. is every raw file present in its associated stem file? Is every stem file present in the associated final mix?)
Upon completion of the error checking process, users are prompted to give information about the naming schema of their files. Finally, a folder containing the raw, stem and mix files is created. The application also reorganizes the files into a standardized structure and naming system while simultaneously creating a metadata file. We hope that the creation of MedleyDeBugger will increase consistency and accuracy of the multitracks in the dataset such that they are as clean and organized as possible for dataset users to utilize.
